I’ve recently had a need to parse HL7 2.x messages stored in SQL Server. If you don’t know what HL7 2.x healthcare messages look like then here’s a quick sample:
MSH|^~\&|HIS|MedCenter|LIS|MedCenter|20060307110114||ORM^O01|MSGID20060307110114|P|2.3 PID|||12001||Jones^John^^^Mr.||19670824|M|||123 West St.^^Denver^CO^80020^USA||||||| PV1||O|OP^PAREG^||||2342^Jones^Bob|||OP|||||||||2|||||||||||||||||||||||||20060307110111| ORC|NW|20060307110114 OBR|1|20060307110114||003038^Urinalysis^L|||20060307110114
Each line in the HL7 message is called a segment and then each segment is split into individual fields by | (pipe) characters (typically). HL7 fields have well-defined names and meanings … for example in the example above PID-3 (the 3rd field in the PID segment where the identifier ‘PID’ is not counted) is 12001 and that represents the patient identifier.
For this particular project I’m working on we have HL7 messages stored in a SQL Server 2016 database table where each row in the table contains the raw HL7 2.x message in a particular column. I need to be able to intelligently filter over this HL7 data by looking at values in particular HL7 fields (as shown above). Since this HL7 data is stored in a varchar(MAX) column I could certainly attempt to play games using LIKE comparisons in SQL but that would not get me very far. SQL simply does not understand the complex structure of HL7 and I have no native SQL Server functions at my disposal that I could quickly use to parse this data and filter it.
I know I must get help from somewhere else. I’ve recently been experimenting with Python and with some quick Google searches I was convinced that Python had some interesting packages that could help with HL7 2.x parsing. Now – keep in mind that this is SQL Server 2016 so SQL Server Machine Learning Services is not available for this version … only for SQL Server 2017 and higher (this is the capability that would enable native execution of R and Python scripts directly in SQL Server T-SQL code). If I can’t run Python code natively in this version of SQL Server then I must execute this Python code from the outside.
I’ve also been looking at Jupyter Notebook recently – an awesome environment for interactive exploration of data sets using languages such as Python – so this was a good excuse to try to bring together all these technologies to enable me to look at HL7 data.
This is not a blog post about Jupyter but if you’d like to take a look at it the easiest way to do it is by installing the Anaconda Distribution which will bring together Jupyter, Python and a ton of other packages and frameworks that are super-useful for data analysis, data science and machine learning.
Once you have Jupyter installed this is the process we’ll follow to deal with HL7 data in SQL Server:
- Connect in Python to SQL Server
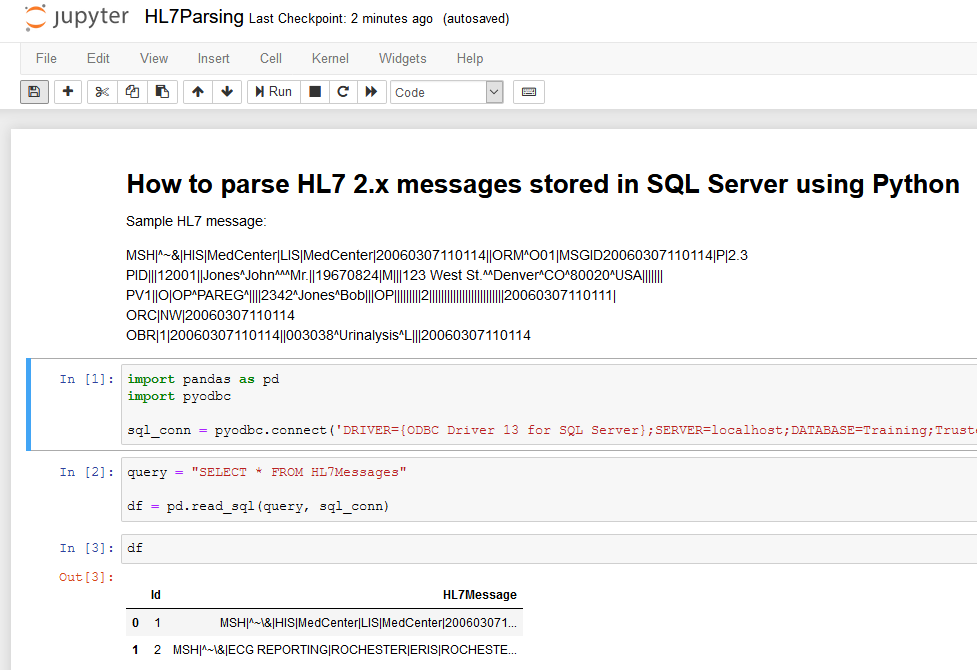
import pandas as pd
import pyodbc
sql_conn = pyodbc.connect('DRIVER={ODBC Driver 13 for SQL Server};SERVER=localhost;DATABASE=Training;Trusted_Connection=yes')
query = "SELECT * FROM HL7Messages"
- Bring data from the SQL Server table into a pandas data frame (pandas is a well known package in Python that makes data exploration really easy)
df = pd.read_sql(query, sql_conn)
- Combine the pandas data frame functionality with HL7 parsing in Python in order to filter HL7 messages as needed
import hl7
for index, row in df.iterrows():
h = hl7.parse(row['HL7Message'])
print("Message type: {}, Patient ID: {}".format(h.segment('MSH')[9], h.segment('PID')[3]))
… which produces the following output using the sample data I was looking at:
Message type: ORM^O01, Patient ID: 12001 Message type: ORU^R01, Patient ID: 999999999
The HL7 parsing functionality in Python is provided by this package:
https://python-hl7.readthedocs.io/en/latest/
If you’d like to follow along you can look at my GitHub repo below where I’ve provided some sample HL7 2.x messages, a SQL script to create a table with that data and Jupyter notebook files to directly execute the relevant Python code:
https://github.com/csatnic/PythonHL7Parsing