![]()
I was recently involved in a project using PostgreSQL on Linux where my goal was to “sprinkle some devops” on the database development process by getting the database schema in source control and automating the schema change deployments. For such a task, in the Microsoft SQL Server ecosystem, I would usually start with SQL Server Data Tools (SSDT). It is a very nice addon included for free with the various tools surrounding SQL Server and it supports my preferred database schema deployments approach – state based deployments. However, for this particular project I was dealing with PostgreSQL and since SSDT does not work with it I had to do some research to see what my options were.
Just a quick aside here – when it comes to deploying schema changes for databases with a strongly enforced schema (this usually means relational database systems) there are two main approaches: state based (the one supported by SSDT above) and migrations based. The focus of my current article is not to define these or to present their pros and cons but I want to include here some excellent reference articles that cover those points very well. It’s important to understand these two approaches because that will make it much easier to relate to the tools you have available to follow
your preferred approach.
- https://samirbehara.com/2018/04/16/database-delivery-state-based-vs-migration-based/
- https://enterprisecraftsmanship.com/posts/state-vs-migration-driven-database-delivery/
- http://workingwithdevs.com/delivering-databases-migrations-vs-state/
So back to my search – I wanted to see what tools I could find for schema deployment automation with PostgreSQL. Since SSDT is a free tool on the SQL Server side I was looking for free / open source options that I could use. I wasn’t able to find any solid open source tools that support the state based approach that SSDT follows and I wasn’t too surpised about it. In the state based approach, the tool used has to do the heavy work: here’s my schema version A and I’d like to get to schema version B … please generate the SQL scripts for me that will allow me to get there. Such a tool would be fairly complex to write and if such open source options would exist they would probably be focused on a particular database engine (since the generated SQL would be engine specific).
Most of the articles I looked at mentioned migration based tools for managing PostgreSQL schema deployments – with two such tools listed in pretty much every article I looked at:
- https://www.liquibase.org/ – Liquibase
- https://flywaydb.org/ – Flyway
Some quick points of comparison between the two:
- both are open source tools with some commercial extensions for advanced features
- both are backed by commercial entities (Liquibase by Datical and Flyway by Redgate)
- both are command-line tools that are Java-based
- Flyway supports migration scripts in plain SQL format while Liquibase supports additional formats such as XML, YAML and JSON (this is useful if you need to migrate schema changes between database systems that don’t use the same SQL dialect)
In the end, for my PostgreSQL needs, I decided to work with Flyway. Why? Here are some quick reasons:
- the GitHub project for Flyway is liked by more than twice the number of followers that Liquibase has (this has to mean something, right?)
- Flyway appeared to me to be the less complex of the two. I didn’t need the advanced features of Liquibase and I was ok with writing migration scripts in SQL (which is what Flyway supports).
- Flyway recently received commercial support from Redgate. I’m very familiar with Redgate’s tools for SQL Server and the fact that they got behind this particular open source project is a good
sign in my book.
After I got Flyway working on PostgreSQL on Linux I started thinking about how Flyway might work with SQL Server on Windows. Why would this matter and why is it a good thing to know?
- I said above that for SQL Server I prefer state based migrations using SSDT – but not everybody does. There are many DBAs working with SQL Server who don’t want to trust a tool (SSDT) to write the migration scripts so for them it’s more natural to use a migrations approach to schema deployments.
- It’s good to be familiar with a database deployment tool that can be used across multiple database engines and operating systems.
- It forced me to understand the deployment workflow needed when migrations are used. It’s always good to see multiple points of view and recognize their pros and cons.
So – how do we use Flyway migration scripts with SQL Server on Windows? Let’s proceed.
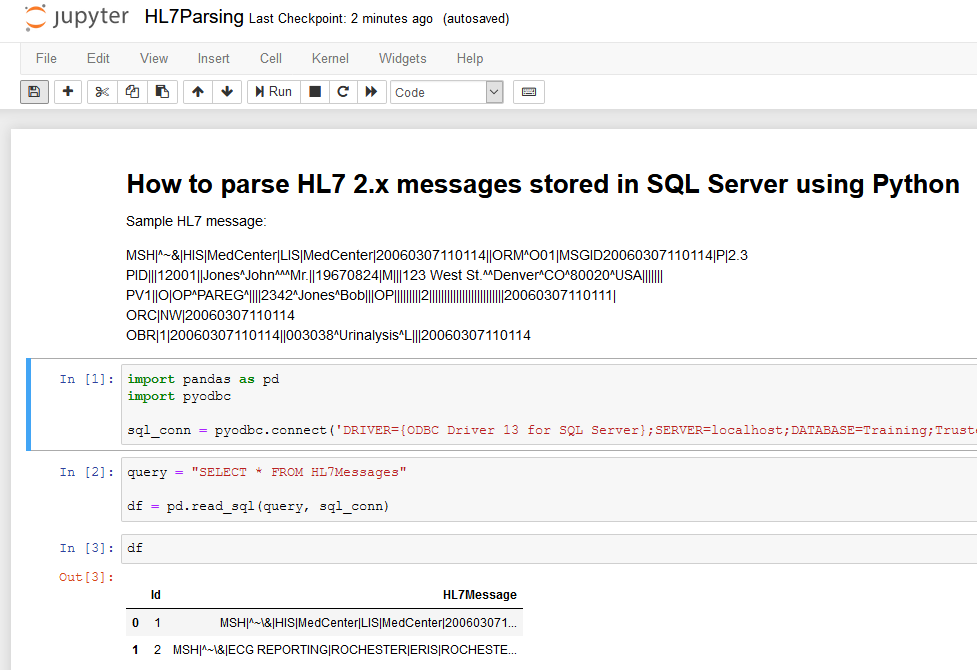
Go to https://flywaydb.org/download/ and download Flyway for Windows. It comes as a zip file so extract the archive and simply add the new flyway-6.2.4 directory to the PATH to make the flyway command available from anywhere on your system. Flyway is distributed with its own JAVA runtime environment (JRE) so you should be able to just type flyway in a command prompt to confirm you’re ready to use it. By default, when called without any parameters, flyway will give you a description of its execution options.
Let’s look at the Flyway directory structure.
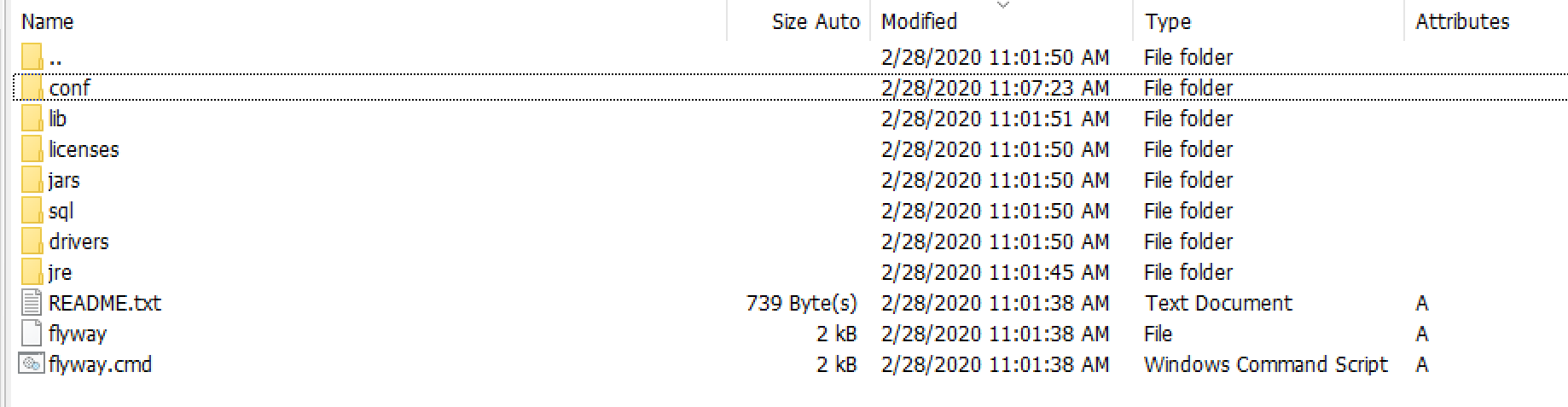
By default, there are 2 folders you want to pay attention to initially. conf is the folder where the Flyway configuration file exists by default and sql is the folder where Flyway will look for SQL migration scripts it needs to execute. Both of these can be modified via configuration parameters but for now we’ll just work with the defaults.
Let’s look at flyway.conf and see what options we need to modify.
flyway.url – the database location (in JDBC format)
flyway.user – user info to use for authentication
flyway.password – the user’s password
flyway.locations – file system locations for the SQL migration files (if you don’t want to use the default /sql folder)
The options above (and many others) are very nicely documented in the configuration file so it should give you a good idea of what’s available and how to configure them.
One word about flyway.url: that config option contains the database name to use for the migration scripts so the database has to exist already. Since creating the database is typically a one-time operation it should be handled outside of the process that delivers the Flyway migrations. In my case, I’m using the following value to point to a local SQL Server database:
flyway.url=jdbc:jtds:sqlserver://localhost:1433/FlywayDemo
Note: the above format is not exactly the one suggested in the config file for SQL Server. I couldn’t get that one to work so I searched for alternate versions and found the one above (thank you StackOverflow).
With the basic configuration options out of the way let’s look now at the Flyway commands that we can work with. There aren’t that many (I did mention that Flyway is simple to use, right?):
migrate – Migrates the database
clean – Drops all objects in the configured schemas
info – Prints the information about applied, current and pending migrations
validate – Validates the applied migrations against the ones on the classpath
undo – [pro] Undoes the most recently applied versioned migration
baseline – Baselines an existing database at the baselineVersion
repair – Repairs the schema history table
Even without knowing much about Flyway or SQL migrations you can probably deduce (by everything you’ve seen above) how Flyway actually works. You, the developer, provide SQL scripts that modify the database schema based on your needs. The only requirement is that you have to name the scripts in a certain way (with version numbers) and place them in the folders that Flyway looks at. When you ask Flyway to migrate a target database schema it will look at the migration scripts it has available, it will figure out the schema version for the target database (using its own Flyway version history table) and it will execute the scripts that are not yet on the target. That’s pretty much all there is to it.
Let’s see what happens when we execute flyway info without any existing migration scripts.
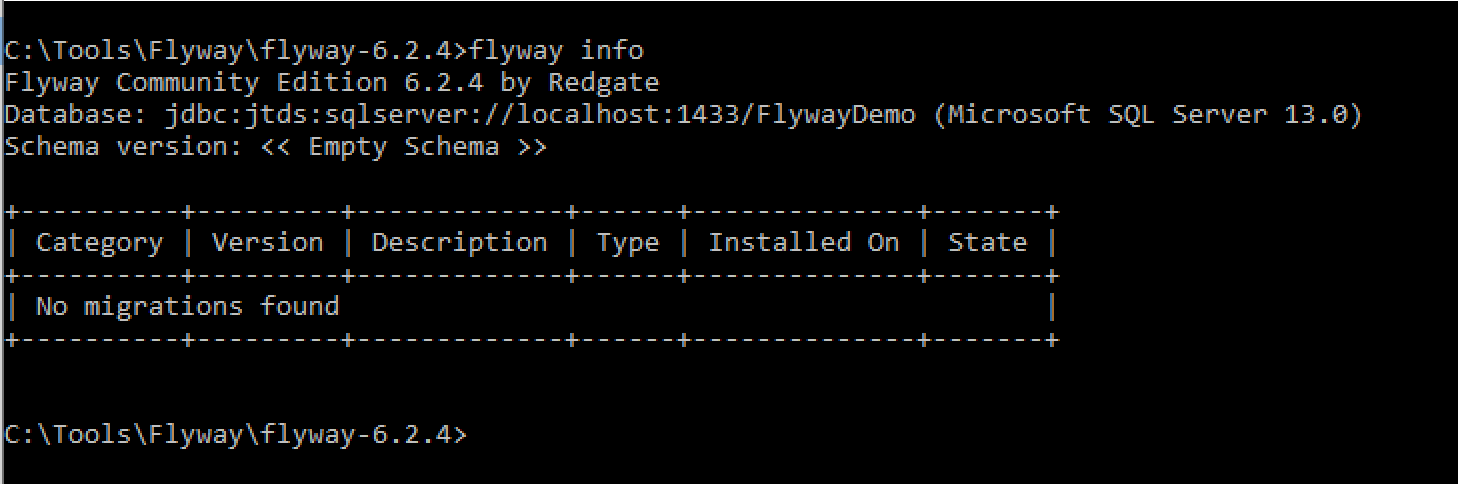
Flyway will attempt to connect to the target and show information about the target’s schema version compared to any migration scripts it finds. In our case we don’t yet have any migration scripts to execute.
Let’s create a script to add a table. By default (and this can be configured – of course) Flyway expects migration scripts to follow a certain naming pattern in order to be picked up.
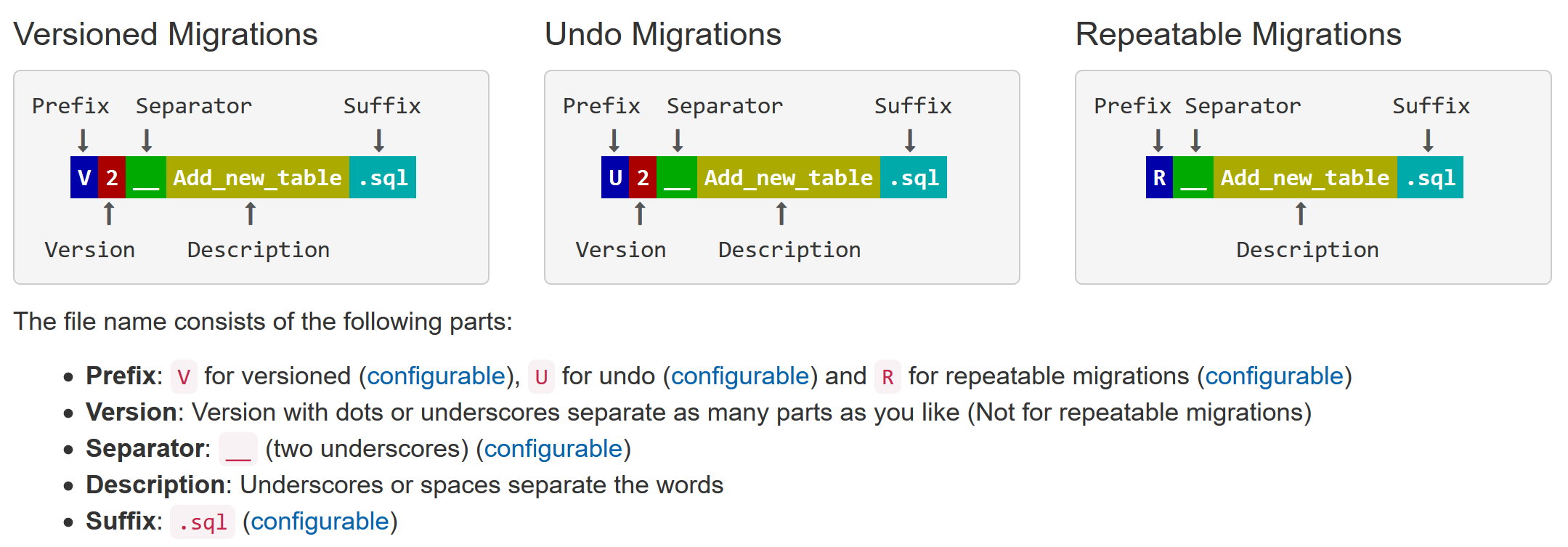
I created a SQL migration script file called V1__add_new_table.sql with the following contents:
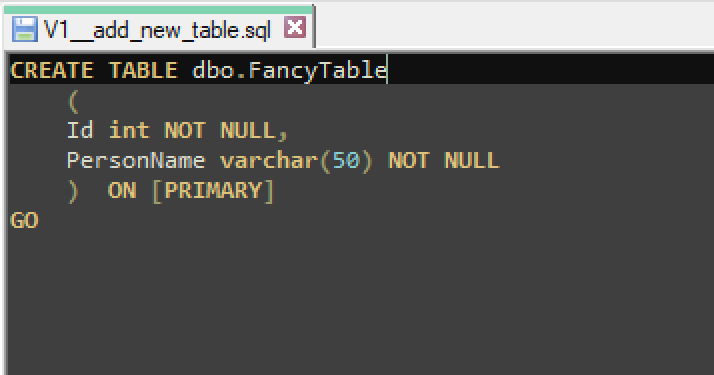
Here’s what happens when we call flyway info (to see if it detects the new migration file), flyway migrate (to apply the migration), and flyway info again to see the result.
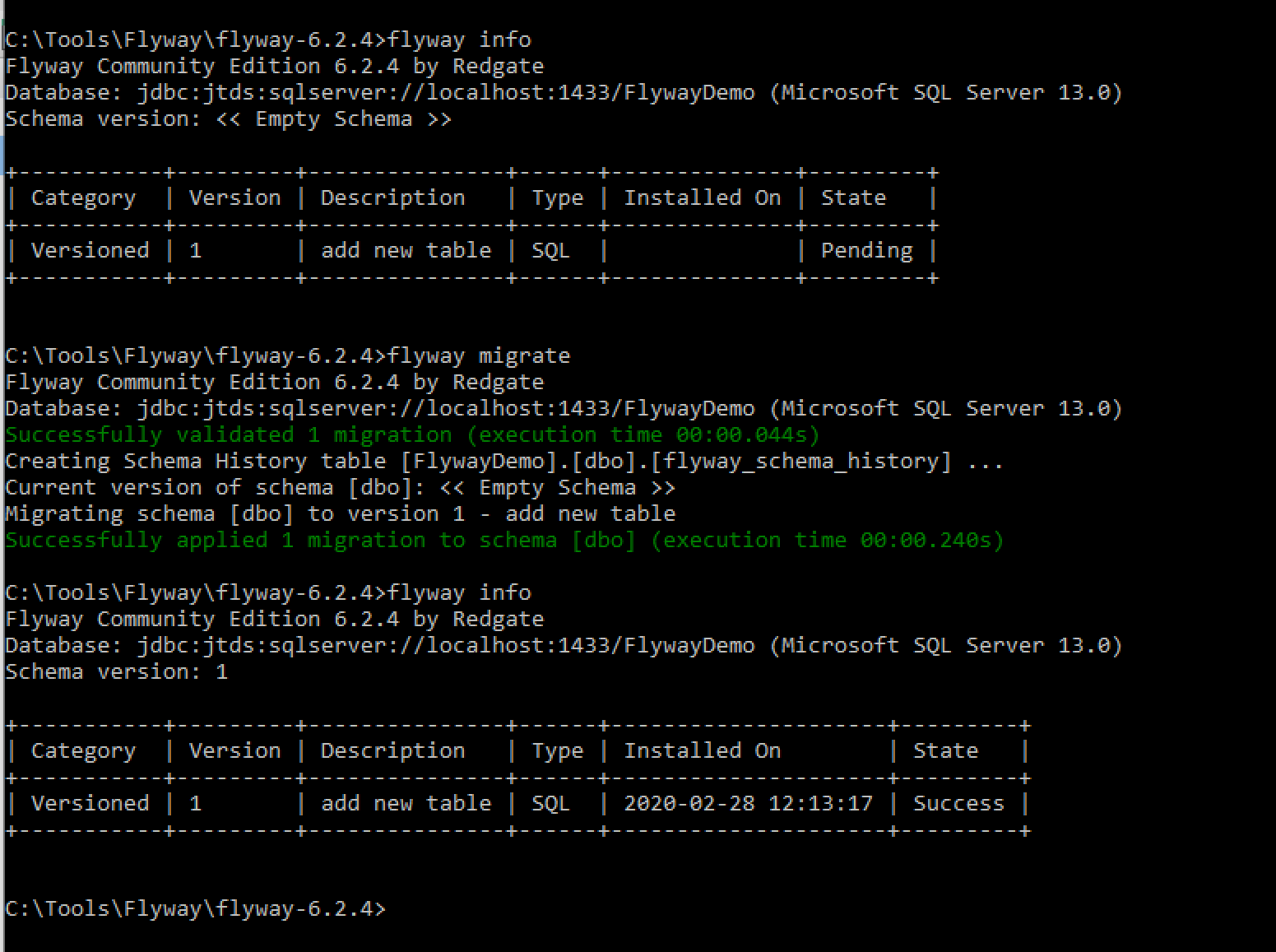
What happened on the SQL Server side?

We see the new table we just created via the migration along with Flyway’s own table for keeping track of schema versions – flyway_schema_history. Let’s see what’s inside that table:

This is pretty much the same information returned by the flyway info command. We looked here at how to get started with Flyway and how to create a versioned migration (those that start with V by default). Versioned migrations, once applied, should never be modified again. Flyway also has the concept of repeatable migrations (those files start with R) – these are migrations that will be executed in the future as long as Flyway detects that the migration file has been modified. Repeatable migrations are useful for scripts that can be easily re-executed (such as those that recreate procedures / views / functions or reinsert bulk data).
One tip that I found useful – how do you execute different migration scripts in different environments? Let’s say that in development you want certain sample data to be present but you don’t want the same data to be found in production. The trick to do that is to put common migration scripts in a common folder (for example) and then have different per-environment folders. When you execute migrations against development you’ll modify the flyway.locations parameter to run scripts from common and the development environment folders and so on for the other environments.
How do you generate the migration scripts to run? Flyway will not help there. It’s up to you to either create them manually or rely on some other tool that can produce the schema diff scripts for you. Flyway will simply execute the scripts it finds in the SQL folders.
How do you use Flyway in a CI/CD pipeline? That depends on the process and tool you use for CI/CD. You could install the Flyway executable directly with your CI/CD environment and use it that way, or, the way I used it with GitLab, you could rely on the fact that Flyway is distributed as a Docker container that you can easily pull in, execute the commands you need, and then throw it away.
Happy SQL schema migrations!